Use understandable variable names Dammit!
Is there anything more annoying than looking through code that has stupid variable names? Im currently tweaking a script that someone else once wrote, a couple of months back maybe and the variable names are like this:
ow, oh, wh, wi, nw, nh, sure i can understand ow = original width and nw being new width. But common?
Seriosuly, people that does this kind of programming should never, ever be working as programmers.
So what do i suggest instead of these riddicilus names? Well back in the time when we had a limit to how many characters we could use, there was a couple of conventions used, but i dont like any of these "short naming"-conventions. Use explaining variable names, such as: image_width, image_height, image_new_width, image_new_height or somewhat like this imageWidth, imageHeight, newImageHeight, newImageWidth. This will make code more understandable and readable.
ow, oh, wh, wi, nw, nh, sure i can understand ow = original width and nw being new width. But common?
Seriosuly, people that does this kind of programming should never, ever be working as programmers.
So what do i suggest instead of these riddicilus names? Well back in the time when we had a limit to how many characters we could use, there was a couple of conventions used, but i dont like any of these "short naming"-conventions. Use explaining variable names, such as: image_width, image_height, image_new_width, image_new_height or somewhat like this imageWidth, imageHeight, newImageHeight, newImageWidth. This will make code more understandable and readable.
Pointers & Double Pointers
Definitions
First off, we need to clearify what a some of the expressions i will use mean. These are the following expressions:
Stack
Assuming that you know about a computer having RAM ( Random Access Memory ) which allows you to store information and have this accessable faster than you would on a secondary memory like a harddrive and/or cd-rom.
When a program is executed there is a part in the memory reserved for this application to use, this "space" is called the Stack; The stack is always the same size and it's not possible to change it's size on any way.
Heap
The Heap is also a "space" on your memory, actually it's all the memory not allocated as a stack. So when your stack is defined, everything else can be expressed as the Heap.
Pointers
What is a pointer really? A pointer is a globally used expression to reference that your somewhat "point" to something. See the following illustration

On this image we have something that we point to, let's call A our Object. So having A as the actualy object, play with the thought that B and C isnt there, and there are no pointers to it.
This would infact mean that we had A allocated on the Stack. When does this become a problem? So play with the thought you have a really big information base such as a User Layer where you store a lot of data on each user. Then havnig a big register on all the people attending a course would take up somewhat a bigger space than we have free.
When is is an issue, we can use a pointer, to reference to this object. You can of course point to an object that you have on the stack, but that's not. afaik, what it's initially intended for.
So we tell our program that we want to create a Pointer, this pointer will in fact be stored on the stack, but a pointer only takes up 4 bytes so this wont be a problem.
After creating the pointer, we create the object itself and have the pointer B point to this.
Pointer, Objects s & Arrays
Assuming you know about some object orientation and how an object is constructed i will not go in to this very deeply. I.e. we have a class called Person and we want to create somewhat a register over students attending a course, what we initially want to do is create an object array, where we can store all our persons, using c++, as i will do in the following examples you would write something like this:
Person *attendingStudents = new Person[size];
Where size is equal to the max amount of students.
Running this code, the constructor of Person will be runned as many times as the size of the array attendingStudents. How is this a problem? This becomes a problem when we dont want to run the default constructor and allocate the object size as many times as the total array size, this has too much overhead.
First of all, how does this look in memory?

On adress 0 to adress 3 wnicn means 4 bytes; every memoy block is 4 bytes; the pointer attendingStudents is allocated and on that area a 4 byte long adress is stored which in our case is 84. The size of the given Person object is not given but just play with the thought that its 4 bytes and the size is 10 this would mean the total size of the Person array would be 10 * 4 = 40 Bytes going from the address 84 to 124.
However, let's say that the Person object takes up 4 times as much so it takes up 16 bytes per Person object, this would result in 16 * 10 = 160 bytes, going from address 84 to 244. Now, there is a big overhead if we dont use all the persons and it would be stupid to call the constructors twice.
So, how about, we just point to something that we know is a pointer, and then let this poitner take care of the rest? But we just initialize the first step?
Double pointers
Thjis is were double pointers comes in handy, look at the following code:
Person **attedningStudents = new Person*[size]:
This code is not as straight forward to look at, as the pervious one, but it basically means,
Person **attendingStudents = Create a reference, to a pointer, what is a pointer? A pointer is something that will in the end point to a data type, so what we do here is saying that Point to a Pointer, this pointer will eventually have the data type Person.
Just to clearify, a pointer to an array, initially points to the first index in that array. So after creating the Pointer to a Pointer we tell it to point to a new list of Pointers, the amount of pointers to create is the same as the digit in size.
This might not make any sense, but take a look at the following

Initally these pointers don't point to anything at all so what we can do is: attendingStudents[i] which will take us to the adress 84 and then create an object on this index by doing this: attendingStudents[i] = new Person();
Why is this method better than the one before? Well this assures that we Only have the 11 pointers which takes 4 bytes per pointer. 1 pointer on the stack, referencing 10 pointers on the stack. When does this give us overhead? This gives us a 4 byte overhead when we start creating our Persons. But the execution time saved and just given 4 bytes ovearhead per pointer, this is a preffered method by me.
First off, we need to clearify what a some of the expressions i will use mean. These are the following expressions:
Stack
Assuming that you know about a computer having RAM ( Random Access Memory ) which allows you to store information and have this accessable faster than you would on a secondary memory like a harddrive and/or cd-rom.
When a program is executed there is a part in the memory reserved for this application to use, this "space" is called the Stack; The stack is always the same size and it's not possible to change it's size on any way.
Heap
The Heap is also a "space" on your memory, actually it's all the memory not allocated as a stack. So when your stack is defined, everything else can be expressed as the Heap.
Pointers
What is a pointer really? A pointer is a globally used expression to reference that your somewhat "point" to something. See the following illustration
On this image we have something that we point to, let's call A our Object. So having A as the actualy object, play with the thought that B and C isnt there, and there are no pointers to it.
This would infact mean that we had A allocated on the Stack. When does this become a problem? So play with the thought you have a really big information base such as a User Layer where you store a lot of data on each user. Then havnig a big register on all the people attending a course would take up somewhat a bigger space than we have free.
When is is an issue, we can use a pointer, to reference to this object. You can of course point to an object that you have on the stack, but that's not. afaik, what it's initially intended for.
So we tell our program that we want to create a Pointer, this pointer will in fact be stored on the stack, but a pointer only takes up 4 bytes so this wont be a problem.
After creating the pointer, we create the object itself and have the pointer B point to this.
Pointer, Objects s & Arrays
Assuming you know about some object orientation and how an object is constructed i will not go in to this very deeply. I.e. we have a class called Person and we want to create somewhat a register over students attending a course, what we initially want to do is create an object array, where we can store all our persons, using c++, as i will do in the following examples you would write something like this:
Person *attendingStudents = new Person[size];
Where size is equal to the max amount of students.
Running this code, the constructor of Person will be runned as many times as the size of the array attendingStudents. How is this a problem? This becomes a problem when we dont want to run the default constructor and allocate the object size as many times as the total array size, this has too much overhead.
First of all, how does this look in memory?
On adress 0 to adress 3 wnicn means 4 bytes; every memoy block is 4 bytes; the pointer attendingStudents is allocated and on that area a 4 byte long adress is stored which in our case is 84. The size of the given Person object is not given but just play with the thought that its 4 bytes and the size is 10 this would mean the total size of the Person array would be 10 * 4 = 40 Bytes going from the address 84 to 124.
However, let's say that the Person object takes up 4 times as much so it takes up 16 bytes per Person object, this would result in 16 * 10 = 160 bytes, going from address 84 to 244. Now, there is a big overhead if we dont use all the persons and it would be stupid to call the constructors twice.
So, how about, we just point to something that we know is a pointer, and then let this poitner take care of the rest? But we just initialize the first step?
Double pointers
Thjis is were double pointers comes in handy, look at the following code:
Person **attedningStudents = new Person*[size]:
This code is not as straight forward to look at, as the pervious one, but it basically means,
Person **attendingStudents = Create a reference, to a pointer, what is a pointer? A pointer is something that will in the end point to a data type, so what we do here is saying that Point to a Pointer, this pointer will eventually have the data type Person.
Just to clearify, a pointer to an array, initially points to the first index in that array. So after creating the Pointer to a Pointer we tell it to point to a new list of Pointers, the amount of pointers to create is the same as the digit in size.
This might not make any sense, but take a look at the following
Initally these pointers don't point to anything at all so what we can do is: attendingStudents[i] which will take us to the adress 84 and then create an object on this index by doing this: attendingStudents[i] = new Person();
Why is this method better than the one before? Well this assures that we Only have the 11 pointers which takes 4 bytes per pointer. 1 pointer on the stack, referencing 10 pointers on the stack. When does this give us overhead? This gives us a 4 byte overhead when we start creating our Persons. But the execution time saved and just given 4 bytes ovearhead per pointer, this is a preffered method by me.
Exam result
I would say that this is probably one of the happiest days of my life, i just finished the Exam in Algorithms and data structures, and i passed :)
Examination in Algorithms and Data Structures
So today i've got the final part of my exam in Algorithms and Data Structures, wish me luck!
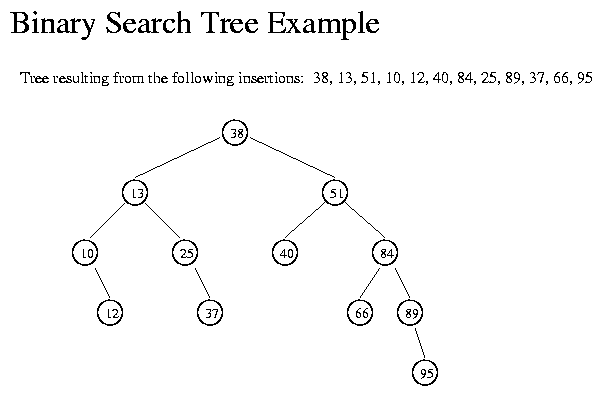
Binary Search Trees is an example of what the exam will cover:
Software Engineering
This image illustrates the fun in Software Engineering, as it also explains the common problems, have fun :)

DirectX 10 FE Game Engine 2.0

So what im going to do is learn some basic DirectX 10, because i am currently using Windows Vista.
I will make a replica of my old Game Engine which can be found at http://frw.se/Engine
There will also be a new version of Brejkipejki available as a demo when my Game Engine is released.
Importance of good Architecture, Structure and Patterns
Often when developing software such as websites, windows ( or any other operative system for that matter ) programs, the begining of the progress is quite simple; you have your ideas and may have some thoughts about how to implement everything. But what often is forgot when developing software is the importance of thinking ahead, thus, planning for a larger software that you have in mind.
For an example, when i started developing SmartIT Invoice i thought of it as a software that would generally help me organize my small amount of invoices. But as the years pass my company grows bigger and bigger and once im up to n-numbers of invoices, a simple List View won't be sufficient. Therefore after implementing my Invoice software, i started thinking about how i could change everything and structure the code for helping me in the future. I had in mind that i might not always want to use the Windows Graphical Interface for input and output so as i always do, i seperate the Design code from the Logical Code. This meaning that my application has three layers. Them being:
Again takng my Invoice softwre as an example, i recently released a software called Webexpress.nu which allows customers to create their own website and for this i need somewhat of a payment system. Of course using Credit card payments is nice and easy but not entierly nessesary. So by just adapting my Webste to the current Logic Data Layer of my SmartIT Invoice software, i could easily get an intergration that allowed me to create customer invoices that pops up on the user account, when they are online on the page of course and even directly to my software, withouth any adjustments in the Data Layer or in my Windows Software.
This proves the point that well structured code and seperate layers will help you along the way of program development.
As a side note the Data Layer in this case is a Windows DLL with .NET 3.5 code which makes it even easier to implement when the website itself is asp.net with .net 3.5.
There are a lot of good design guidelines out there which will help you structure your software better and help you understand how to always follow a pattern. A pattern doesn't, in my point of view, have to be a pattern like Singelton etc, it can by any means be a way for yourself to regocnize your own code, thus following a pattern. Example, i often tend to use m_ before member variables and write all functions and access methods with a capital letter.
Have fun programming!
For an example, when i started developing SmartIT Invoice i thought of it as a software that would generally help me organize my small amount of invoices. But as the years pass my company grows bigger and bigger and once im up to n-numbers of invoices, a simple List View won't be sufficient. Therefore after implementing my Invoice software, i started thinking about how i could change everything and structure the code for helping me in the future. I had in mind that i might not always want to use the Windows Graphical Interface for input and output so as i always do, i seperate the Design code from the Logical Code. This meaning that my application has three layers. Them being:
- Application Layer, code for display, handling window events
- Logic data layer, database connections, objects
- Data layer, this being the database with functions, views and procedures
Again takng my Invoice softwre as an example, i recently released a software called Webexpress.nu which allows customers to create their own website and for this i need somewhat of a payment system. Of course using Credit card payments is nice and easy but not entierly nessesary. So by just adapting my Webste to the current Logic Data Layer of my SmartIT Invoice software, i could easily get an intergration that allowed me to create customer invoices that pops up on the user account, when they are online on the page of course and even directly to my software, withouth any adjustments in the Data Layer or in my Windows Software.
This proves the point that well structured code and seperate layers will help you along the way of program development.
As a side note the Data Layer in this case is a Windows DLL with .NET 3.5 code which makes it even easier to implement when the website itself is asp.net with .net 3.5.
There are a lot of good design guidelines out there which will help you structure your software better and help you understand how to always follow a pattern. A pattern doesn't, in my point of view, have to be a pattern like Singelton etc, it can by any means be a way for yourself to regocnize your own code, thus following a pattern. Example, i often tend to use m_ before member variables and write all functions and access methods with a capital letter.
Have fun programming!
Halting problem
Yesterday i accounted a very fun problem which has a mathematically incomputable solution. Meaning; the solution cannot and will never be able to be stated as a mathematical formula. Let me take this from the begining. There is a known problem called "The halting problem".
The first thing we ask ourselves; Is it generally possible to prove that a program has bugs in it or not, for all possible inputs?
The answer is False, this is impossible and here's another view of the problem;
Is it generally possible to prove that a program will eventually halt or weather it will loop forever, for all possible inputs?
Same answer here, this is False
We have this function public boolean Halts(string program, object[] arguments);
And now we have
public static void UhOh(string program) { if (Halts(program)) for(;;); else return; }
What happens when the argument is the program itself? Then the result will be:
If i Halt: Loop forever
If i loop: Halt
Which takes us back to square one, this problem is impossible to solve.
This is called The halting problem, read more here: http://en.wikipedia.org/wiki/Halting_problem
Now, of course there is a solution, why else would i bother repeating this? :)
The Busy Beaver Set is the solution to our problem, this Set of numbers will help us, however, the Busy Bever Set is impossible to compute with mathematics. Which makes this theory impossible to prove. Im not gonna state how the BBS works but it will generally help us try out 4 > 5 instruction long sequences which makes it possible to try over billions of inputs. Its still not infinity though.
Special thanks to Chris from Glasgow, Software Engineere.
The first thing we ask ourselves; Is it generally possible to prove that a program has bugs in it or not, for all possible inputs?
The answer is False, this is impossible and here's another view of the problem;
Is it generally possible to prove that a program will eventually halt or weather it will loop forever, for all possible inputs?
Same answer here, this is False
We have this function public boolean Halts(string program, object[] arguments);
And now we have
public static void UhOh(string program) { if (Halts(program)) for(;;); else return; }
What happens when the argument is the program itself? Then the result will be:
If i Halt: Loop forever
If i loop: Halt
Which takes us back to square one, this problem is impossible to solve.
This is called The halting problem, read more here: http://en.wikipedia.org/wiki/Halting_problem
Now, of course there is a solution, why else would i bother repeating this? :)
The Busy Beaver Set is the solution to our problem, this Set of numbers will help us, however, the Busy Bever Set is impossible to compute with mathematics. Which makes this theory impossible to prove. Im not gonna state how the BBS works but it will generally help us try out 4 > 5 instruction long sequences which makes it possible to try over billions of inputs. Its still not infinity though.
Special thanks to Chris from Glasgow, Software Engineere.
Big O-notation
So starting school in a couple of weeks and being told that you wont get any "allowance" from the state makes you think twice about your current situtation. Not that this has anything ( directly ) to do with o-notation. However this is how i forced myself into learning it. I have to re-take an exam in Algorithms and Datastructures this upcoming week and i want to share my experience in big o-notation.
So basicly we have an array, a list of some sort and somehow we need to go through each element in this list. Having 'n' elements we need to create some kind of look like this:
void walkList(int[] numbers)
{
for ( int i = 0 ; i < numbers.lenght(); i ++ )
{
print numbers[i];
}
}
Now this will print all the elements contained in the list of numbers. Lets look at this from a time complexity way, 4 constant operations these being:
Now lets say we need to process ths array in another way, play with the thought that we have this list of numbers and for each number we want to go through the list again. This would give us a nested loop and give the time complexity O(n^2). This meaning that we need to process the list twice for each item, hence n ^ 2.
Looking at a sorting algorithm like Merge Sort that first divides the list into 2 peices untill its at the last item, then merges them. We see the typical behavior of a log() with the base 2. So, the split / sort part is basicly log(n) while the merging part is n and log (n) * n = nlog(n) which is slower than log(n). There are however no "standard" sort algorithms that can do better than nlog(n), in a random case that is. Best case for i.e. bubblesort is log(n) and worst case for bubblesort is log(n^2) which is slower than mergesort.
Mergesort

When is time complexity nessesary? I would say that during all my years of programming, learning speed, size and other performance parts the hard way, i would say that this is a very good complement to fast calculate time complexity of your algorithm. You can be a very good programmer without knowing a lot about this. A lot of this is just something that a programmer knows how to handle without knowing O-notation. But as said, a good complement.
Have fun programming.
So basicly we have an array, a list of some sort and somehow we need to go through each element in this list. Having 'n' elements we need to create some kind of look like this:
void walkList(int[] numbers)
{
for ( int i = 0 ; i < numbers.lenght(); i ++ )
{
print numbers[i];
}
}
Now this will print all the elements contained in the list of numbers. Lets look at this from a time complexity way, 4 constant operations these being:
- function input
- int i assignment
- i < numbers check
- increment
Now lets say we need to process ths array in another way, play with the thought that we have this list of numbers and for each number we want to go through the list again. This would give us a nested loop and give the time complexity O(n^2). This meaning that we need to process the list twice for each item, hence n ^ 2.
Looking at a sorting algorithm like Merge Sort that first divides the list into 2 peices untill its at the last item, then merges them. We see the typical behavior of a log() with the base 2. So, the split / sort part is basicly log(n) while the merging part is n and log (n) * n = nlog(n) which is slower than log(n). There are however no "standard" sort algorithms that can do better than nlog(n), in a random case that is. Best case for i.e. bubblesort is log(n) and worst case for bubblesort is log(n^2) which is slower than mergesort.
Mergesort
When is time complexity nessesary? I would say that during all my years of programming, learning speed, size and other performance parts the hard way, i would say that this is a very good complement to fast calculate time complexity of your algorithm. You can be a very good programmer without knowing a lot about this. A lot of this is just something that a programmer knows how to handle without knowing O-notation. But as said, a good complement.
Have fun programming.
Objects, Objects, Objects!
By looking on everything in life as Objects is one of the benefits from doing object oriented programming. It doesn't really matter if you master the technique or if you are in the beginners stage, just starting with object oriented programming will open up your eyes.
Seeing how objects change your perspective on both programming and other stuff in life, i've notied that when i wanted to learn something like animating in Flash, knowing object orientation helps. Not particulary with the animating, but with the thoughts on how i will structure my animations.
I.e. that i have to create a move, where a part in this move occures many times, repeatinly creating this scenes and moving them around is a fairly harsh work. Looking at it from an object oriented perspective you see that you have:
A main film
An object containging the scene
When needed, you just insert a new object of the scene and you never need to repeate the procedure of creating the scene.
Using Objects isn't always good though, when you need to store the memory on other medias than the RAM you need it to be serialized, which is not handled to good by some languages such as PHP.
The basics of object orientation is easy to learn over a few minutes, when you try to look at everthing at a new perspective, the learning period will decrease.
Let's say that you have a Car, this car has 4 wheels, 5 doors, 6 windows and so on. The doors got handles, the wheels got air in them and so on. Seeing all these parts as Objects is a good way to play with the thoughts of object orientation. See how i apply inheritage on a car:
abstract class BasePart
{
int m_ModelNr;
string m_Name;
public BasePart(int ModelNumber, string Name)
{
m_ModelNr = ModelNumber;
m_Name = Name;
}
}
Everytime you create something, the created part / object or wathever got a Model Number and a Name, just look at carparts or a coka cola bottle.
class Door : BasePart
{
int m_DoorType;
int m_Weight;
int m_Code;
public Door(int DoorType, int Weight, int Code, int ModelNumber, int Name) : base(ModelNumber, Name)
{
///.....
}
}
The codesnippet above shows the basics in object orientation, this is a Base Class which is Abstract, which means that you cannot create an object of it.
The Door is derived from a BasePart because its a BasePart.
Futher object orientation overviews and thoughts will come soon!
Seeing how objects change your perspective on both programming and other stuff in life, i've notied that when i wanted to learn something like animating in Flash, knowing object orientation helps. Not particulary with the animating, but with the thoughts on how i will structure my animations.
I.e. that i have to create a move, where a part in this move occures many times, repeatinly creating this scenes and moving them around is a fairly harsh work. Looking at it from an object oriented perspective you see that you have:
A main film
An object containging the scene
When needed, you just insert a new object of the scene and you never need to repeate the procedure of creating the scene.
Using Objects isn't always good though, when you need to store the memory on other medias than the RAM you need it to be serialized, which is not handled to good by some languages such as PHP.
The basics of object orientation is easy to learn over a few minutes, when you try to look at everthing at a new perspective, the learning period will decrease.
Let's say that you have a Car, this car has 4 wheels, 5 doors, 6 windows and so on. The doors got handles, the wheels got air in them and so on. Seeing all these parts as Objects is a good way to play with the thoughts of object orientation. See how i apply inheritage on a car:
abstract class BasePart
{
int m_ModelNr;
string m_Name;
public BasePart(int ModelNumber, string Name)
{
m_ModelNr = ModelNumber;
m_Name = Name;
}
}
Everytime you create something, the created part / object or wathever got a Model Number and a Name, just look at carparts or a coka cola bottle.
class Door : BasePart
{
int m_DoorType;
int m_Weight;
int m_Code;
public Door(int DoorType, int Weight, int Code, int ModelNumber, int Name) : base(ModelNumber, Name)
{
///.....
}
}
The codesnippet above shows the basics in object orientation, this is a Base Class which is Abstract, which means that you cannot create an object of it.
The Door is derived from a BasePart because its a BasePart.
Futher object orientation overviews and thoughts will come soon!
MySQL : Limit + Order By is Slow
Play with the thought you are having a table strucutre like this:
[ Persons ]
ID
Name
[ Occupations ]
ID
Identification
[ Occupation_Relation ]
UserID
OccupationID
Having Indices on all nessesary columns and using a query like this:
select Persons.Name, Occupation.Identification
from Occupation_Relation
inner join Persons
on Occupation_Relation.UserID = Persons.ID
inner join Occupations
on Occupation_Relation.OccupationID = Occupations.ID
where Idenfitication in ('IT')
order by Name
limit 0, 20
This will be VERY slow because having 200 000 Occupation Relations regarding IT, it will use the Order By clause before the limit, thus ordering 200 000 rows.
The simple solution to this problem is having a subselect like this
select Persons.Name, Occupation.Identification
from ( select Persons.Name, Occupation.Identification from Occupation_Relation inner join Persons on Occupation_Relation.UserID = Persons.ID inner join Occupations on Occupation_Relation.OccupationID = Occupations.ID where Idenfitication in ('IT')
limit 0, 20
)
order by Name
This will though give us a major problem having thrown away hunders of thousands of rows. But this will give us 2000 relevant rows to our search and thus solving the performance problem.
The solution forces the User to specifiy the specific searched data.
[ Persons ]
ID
Name
[ Occupations ]
ID
Identification
[ Occupation_Relation ]
UserID
OccupationID
Having Indices on all nessesary columns and using a query like this:
select Persons.Name, Occupation.Identification
from Occupation_Relation
inner join Persons
on Occupation_Relation.UserID = Persons.ID
inner join Occupations
on Occupation_Relation.OccupationID = Occupations.ID
where Idenfitication in ('IT')
order by Name
limit 0, 20
This will be VERY slow because having 200 000 Occupation Relations regarding IT, it will use the Order By clause before the limit, thus ordering 200 000 rows.
The simple solution to this problem is having a subselect like this
select Persons.Name, Occupation.Identification
from ( select Persons.Name, Occupation.Identification from Occupation_Relation inner join Persons on Occupation_Relation.UserID = Persons.ID inner join Occupations on Occupation_Relation.OccupationID = Occupations.ID where Idenfitication in ('IT')
limit 0, 20
)
order by Name
This will though give us a major problem having thrown away hunders of thousands of rows. But this will give us 2000 relevant rows to our search and thus solving the performance problem.
The solution forces the User to specifiy the specific searched data.